摘自简书:NoSQL 还是 SQL ?这一篇讲清楚
- NoSQL历史

传统数据库的缺点
- 大数据IO成本大
- 即使只计算一列,也会把整行读取进内存
- 存储的是行记录
- 无法存储数据结构
- 表的结构拓展不方便
- 修改表的结构,期间会导致锁表
- 全文搜索功能较弱
- 关系型数据库下只能够进行子字符串的匹配查询,表的数据逐渐变大时,like会变的非常慢,即使有索引
- 存储和处理复杂关系型数据功能较弱
- 表格数据模型和严格的模式使它们很难添加新的或不同种类的关联信息
列式数据库
以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理和即时查询
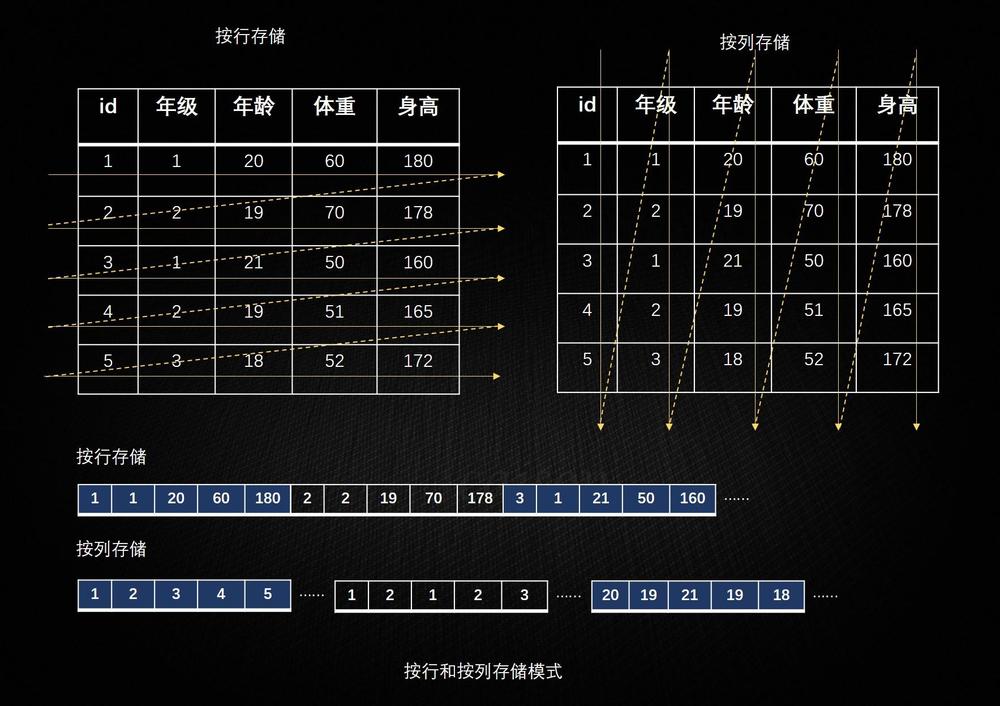
以HBase说明
- 优点
- 解决了大数据情境下高IO的问题
- 查询效率高
- 适合做聚合操作
- 适合大量的数据
- 缺点
- 不适合小量数据
- 不适合随机更新
- 不适合做删除和更新的实时操作
- 单行的数据是ACID的,多行的事务时,不支持事务的正常回滚。不能保证事务的ACID中的A和C
常见的K-V数据库
指的是使用键值(key-value)存储的数据库,其数据按照键值对的形式进行组织、索引和存储。
以Redis为例
-
优点
-
性能高
-
支持超过10W的吞吐量
QPS(TPS):每秒钟request/事务 数量
并发数: 系统同时处理的request/事务数
响应时间: 一般取平均响应时间
-
-
丰富的数据类型
-
丰富的特性
- 支持发布/订阅
-
-
缺点
- 针对ACID,不支持A和D
- 这里所说的无法保证原子性,是针对Redis的事务操作,因为事务是不支持回滚(roll back),而因为Redis的单线程模型,Redis的普通操作是原子性的
- 针对ACID,不支持A和D
文档数据库
文档数据库通常以 JSON 或 XML 格式存储数据。
以MongoDB为例
-
优点
- 新增字段简单
- 无需执行DDL语句
- 容易兼容历史数据
- 即使没有新增字段,也不会导致错误,只会返回空值
- 容易存储复杂数据
- JSON容易描述复杂的数据结构
- 新增字段简单
-
缺点
- 主要是对多条数据记录的事务支持较弱
- A
- 只支持单行/文档级别的原子性
- I
- 隔离仅支持已经提交的读级别,可能导致补课重复读,幻读的问题
- 不支持复杂的查询
- 需要需要join查询,需要多次操作数据库
- A
- 主要是对多条数据记录的事务支持较弱
全文搜索引擎
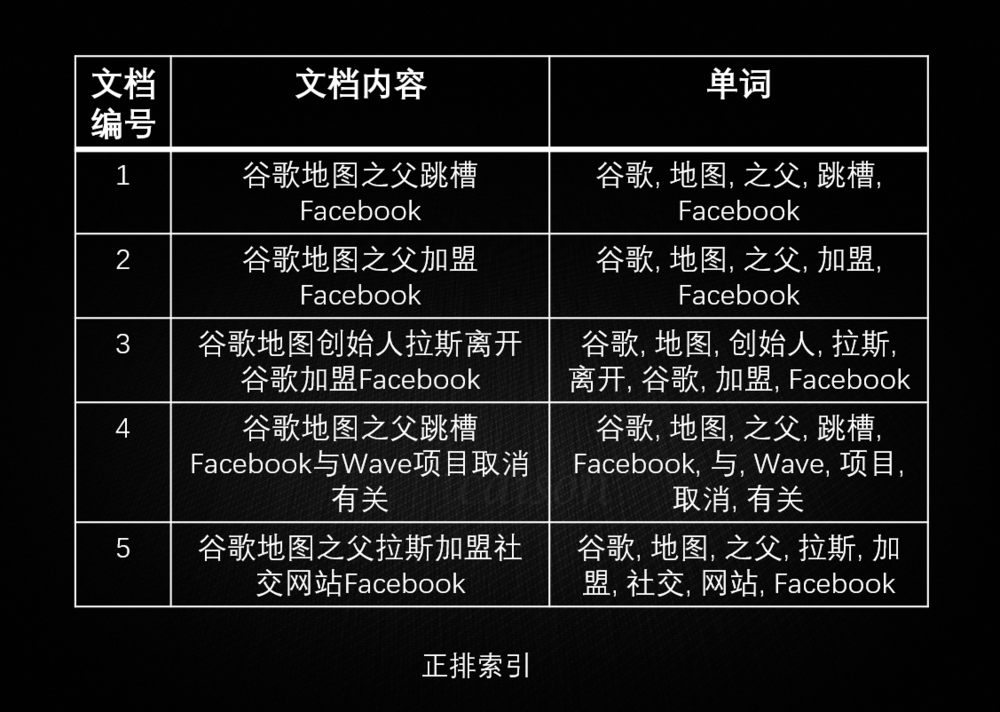
在全文搜索下,解决关系型数据库全文搜索功能较弱的问题。运用的是倒排索引。
正排索引
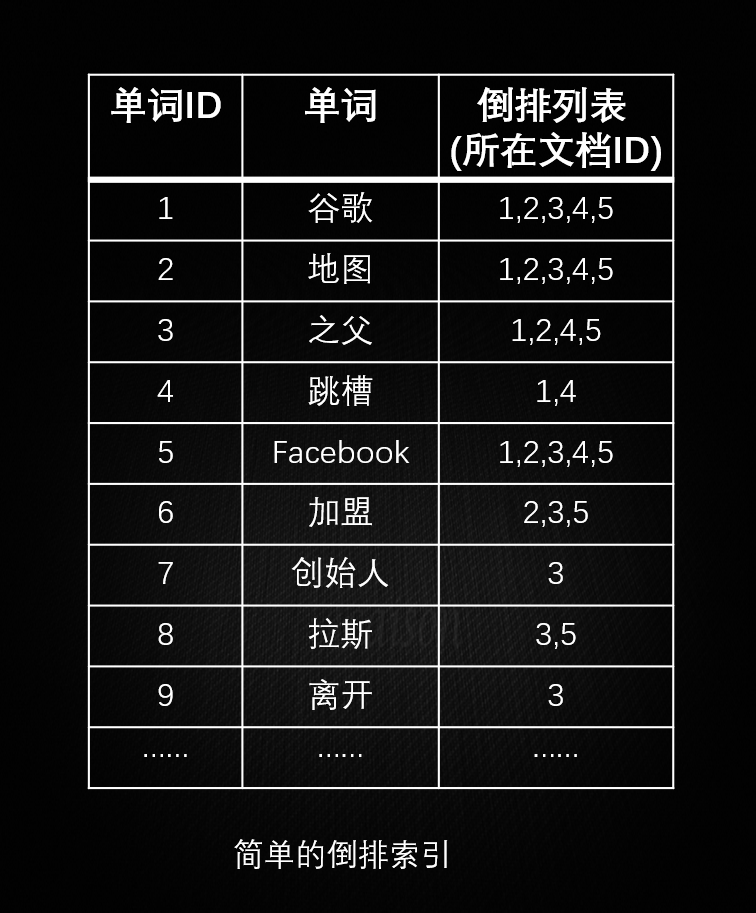
改变为倒排索引后:
以Elasticsearch为例
- 优点
- 查询效率高
- 可拓展性
- 基于集群的环境考验方便横向拓展,考验承载PB级数据
- 高可用
- 集群弹性,可及时发现新的或者失败的节点,重组或者重新平衡
- 缺点
- ACID支持不足
- 对于多文档事务,不支持A和C
- 对类似数据库中通过外键的复杂的多表关联操作支持弱
- 读写有延迟
- 更新性能低,底层是删除再插入
- 内存占用大,要存放索引到内存
- ACID支持不足
图形数据库
…
总结
关系型数据库和NoSQL数据库的选型,往往需要考虑几个指标:
- 数据量
- 并发量
- 实时性
- 一致性要求
- 读写分布和类型
- 安全性
- 运维成本
常见软件系统数据库选型参考如下:
- 内部使用的管理型系统 如运营系统,数据量少,并发量小,首选考虑关系型
- 大流量系统 如电商单品页,后台考虑选关系型,前台考虑选内存型
- 日志型系统 原始数据考虑选列式,日志搜索考虑选倒排索引
- 搜索型系统 例如站内搜索,非通用搜索,如商品搜索,后台考虑选关系型,前台考虑选倒排索引
- 事务型系统 如库存,交易,记账,考虑选关系型型+缓存+一致性型协议
- 离线计算 如大量数据分析,考虑选列式或者关系型也可以
- 实时计算 如实时监控,可以考虑选内存型或者列式数据库
设计实践中,要基于需求、业务驱动架构,无论选用RDB/NoSQL/DRDB,一定是以需求为导向,最终数据存储方案必然是各种权衡的综合性设计

